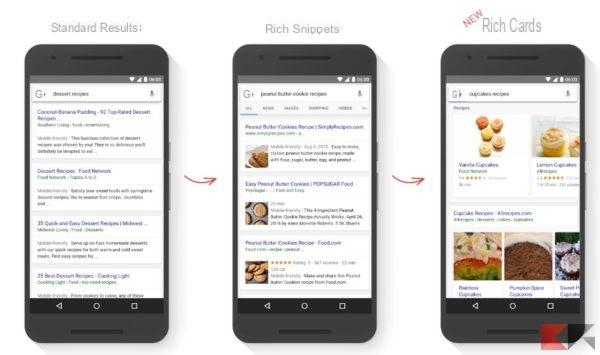



Mountain View (États-Unis) - Google a ajouté une application, appelée Tesseract, pour la reconnaissance optique de caractères (OCR) à son impressionnante collection de logiciels gratuits. C'est un programme qui peut être utilisé pour convertir le texte contenu dans une image, généralement obtenu au moyen d'un scanner, en caractères qui peuvent être compris par un traitement de texte.
Le moteur derrière Tesseract a été créé à l'origine par HP , qui a pourtant cessé de se développer depuis 1995 : ceci malgré le fait qu'à l'époque il était considéré comme l'un des meilleurs logiciels d'OCR du moment. Il y a environ deux ans, HP a fait don du code à l'Université du Nevada à Las Vegas (UNLV), qui travaille depuis à corriger les bogues. Depuis quelques mois, Google a pris le parrainage de l'initiative en faire un projet open source et maintenant il affirme que le programme "est suffisamment stable pour être republié en open source".
Tesseract souffre cependant toujours de quelques limitations importantes : le premier est le support de la langue anglaise uniquement (pas de correcteur orthographique italien, pour ainsi dire) ; la seconde est l'incapacité de conserver la mise en page des pages (comme les colonnes et les tableaux) ; le troisième est la mauvaise capacité à reconnaître les textes imprimés sur des feuilles grises ou en couleur (en d'autres termes, il ne donne le meilleur qu'avec du texte classique noir sur blanc). De l'aveu même de Google, Tesseract il est beaucoup moins précis que les meilleurs packages OCR sur le marché aujourd'hui .
Il faut également considérer que, bien que les développeurs d'UNLV aient corrigé le code ici et là, la technologie derrière Tesseract est restée essentiellement la même qu'il y a dix ans.
Cependant, Google prétend que Tesseract " il est beaucoup plus précis que n'importe quel OCR open source " », De plus, sa licence permet à quiconque de l'améliorer et de l'intégrer dans d'autres applications : ce qui n'est pas une mince affaire.
Le grand G a promis qu'il continuerait à travailler avec ce logiciel, et à cette fin, il embauche des experts en technologies liées à cet OCR.
Que Google s'intéresse à l'OCR n'est pas surprenant : BigG fait grand usage de cette technologie pour la numérisation de livres (voir Google Book Search), de plus, en tant que moteur de recherche, il s'intéresse particulièrement à accélérer la transition de toutes les connaissances humaines vers des formats numériques indexables par ses araignées .
Tesseract n'est actuellement disponible que sous forme de code source, qui peut être téléchargé à partir de cette page SourceForge.net.
Google lance un OCR open source